

第二波 DeepSeek 衝擊:V3.2 改寫中國雲生態與芯片生態

摩根大通表示,,DeepSeek V3.2 通過稀疏注意力機制實現架構革命,推理能力達 GPT-5 水平,每百萬 tokens 輸入僅 0.28 美元,API 價格下降 30-70%,長文本推理成本暴降 6-10 倍。更關鍵的是首次實現對華為昇騰、寒武紀等國產芯片的” Day-0” 首日支持,打破對英偉達依賴。
DeepSeekV3.2 的發佈標誌着中國 AI 市場正式進入 “第二波衝擊” 階段。
12 月 6 日,據硬 AI 消息,摩根大通在研報中稱,這不僅僅是一次模型迭代,更是一場針對推理成本和硬件生態的結構性革命。DeepSeek 通過架構創新將 API 價格再度下壓 30-70%,使得長上下文推理成本暴降 6-10 倍。
研報強調,更為關鍵的是,V3.2-Exp 實現了對非 CUDA 生態(華為昇騰、寒武紀、海光)的 “Day-0” 首日支持,徹底打破了前沿模型對英偉達硬件的依賴路徑。
據摩根大通分析,受益者包括雲運營商阿里巴巴、騰訊、百度,以及芯片製造商中微公司、北方華創、華勤技術和浪潮信息。預計 V3.2 模型將在未來幾個季度進一步提升生成式 AI 在中國的普及率。
據華爾街見聞文章,12 月 1 日,DeepSeek 發佈 V3.2 系列兩款模型並開源。V3.2 主打日常應用,推理能力達 GPT-5 水平,首次實現思考模式與工具調用融合;V3.2-Speciale 專注極致推理,在 IMO、CMO、ICPC、IOI 四項國際競賽中斬獲金牌。
性能與架構:效率的極致壓榨與 “智能體” 進化
DeepSeekV3.2 並非單純堆砌參數,而是通過算法層面的創新實現了效率的質變。該模型延續了 V3.1 的混合專家(MoE)架構主體,但引入了 DeepSeek 稀疏注意力機制(DSA)。
摩根大通指出,作為 9 月 29 日首次發佈的實驗性 V3.2-Exp 模型的後續產品。V3.2 模型通過持續訓練引入了 DeepSeek 稀疏注意力機制(DSA),這是唯一的架構變動,減少了長上下文計算,同時保持了在公開基準測試中的水準。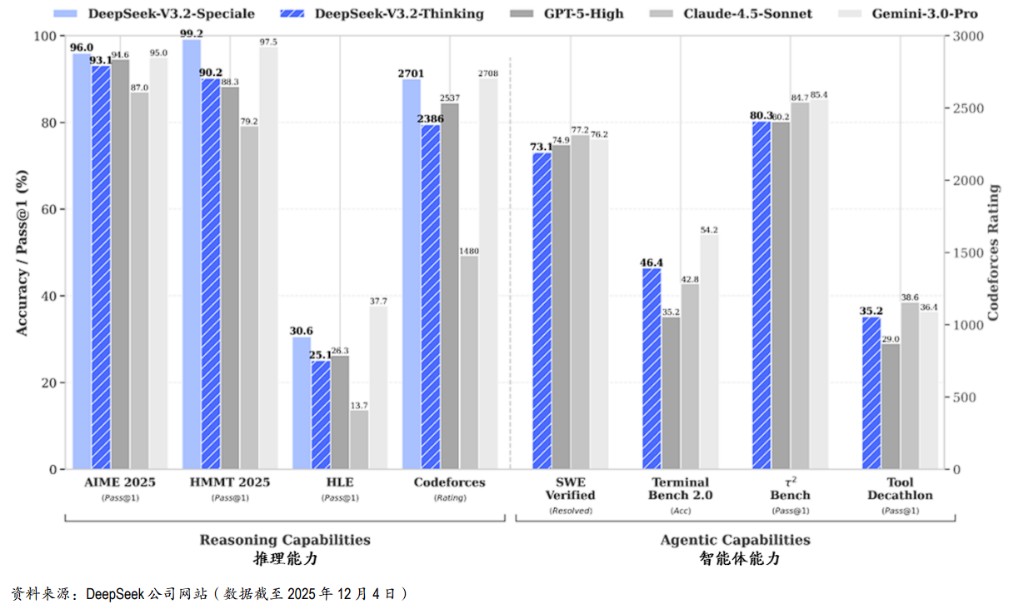
具體來看,主要包括以下四個方面:
架構突破:DSA 機制通過閃電索引器選擇關鍵鍵值條目,將長上下文情境下的計算複雜度從平方級(O(L2))直接降維至準線性級(O(L·k))。
性能數據:在 128ktokens 的長文本環境下,V3.2 的推理速度較前代提升 2-3 倍,GPU 內存佔用減少 30-40%,且模型性能不僅沒有退步,反而保持了極高水準。
智能體定位:V3.2 被明確定位為 “為 Agent 構建的推理優先模型”。它實現了 “思考 + 工具調用” 的深度交錯——模型可以在單一軌跡中結合思維鏈與工具調用(API、搜索、代碼執行)。
高端版本:Speciale 版本在奧林匹克級數學競賽和競爭性編程中表現優異,其推理基準已媲美 Gemini3.0Pro 和 GPT-5 級系統。

定價革命:通縮的推理經濟學
摩根大通指出,DeepSeekV3.2 的發佈再次確立了其 “價格屠夫” 的地位,尤其是在與美國頂級模型的對比中,展現了驚人的性價比優勢。
研報認為,DSA 架構帶來的效率提升直接轉化為了 API 的結構性降價。具體表現為:
具體定價:V3.2Reasoning 的每百萬 tokens 輸入價格降至 0.28 美元,輸出價格降至 0.42 美元。
降幅對比:相比 2025 年 9 月發佈的 V3.1Reasoning(輸入 0.42/輸出 1.34 美元),輸出成本暴跌 69%,輸入成本降低 33%。相比 2025 年 1 月的 R1 模型,價格優勢更加呈指數級擴大。

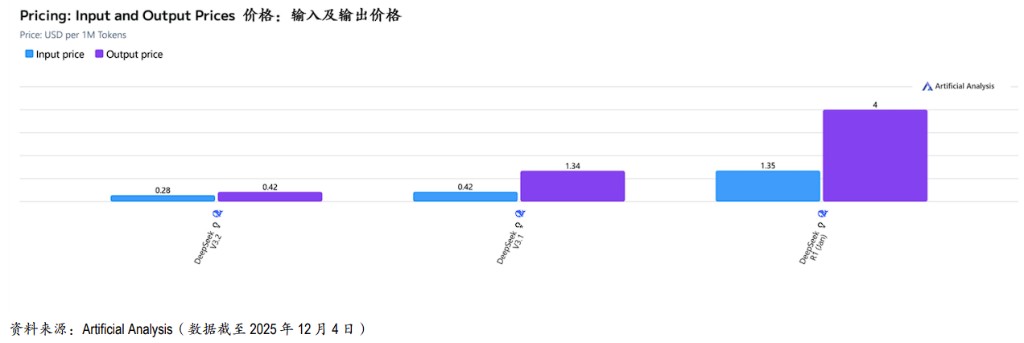
據摩根大通分析,根據第三方基準,部分長上下文推理工作負載的實際成本降低了 6-10 倍。這種定價策略迫使市場重新定義 “前沿級” 能力的成本基準,對所有競爭對手造成巨大的下行定價壓力。
在 ArtificialAnalysis 的智能指數與價格對比中,DeepSeekV3.2 處於 “高智能、極低價格” 的絕對優勢象限。
生態重構:國產芯片的 “Day-0” 時刻
據研報,DeepSeekV3.2 標誌着中國 AI 模型從單純依賴英偉達 CUDA 生態,轉向對國產硬件的主動適配。
摩根大通稱,V3.2-Exp 是首批在發佈首日(Day-0)即針對非 CUDA 生態進行優化的前沿模型,支持包括華為的 CANN 堆棧和 Ascend(昇騰)硬件、寒武紀的 vLLM-MLU 以及海光的 DTK。
這向市場發出了強烈的信號——GPT-5 級別的開源模型可以在國產加速器上高效運行。這將由下至上降低中國 AI 買家的執行風險,直接帶動對國產 AI 芯片和服務器的增量需求。
