

AI 服務器需求大增, 核心電子器件迎來廣闊空間

AI服务器核心电子硬件梳理

AI服务器简介
AI模型的训练和推理:(1)训练是指,通过对海量数据的学习,神经网络找到海量数据集中的给定的输入与结果之间的关系(搭建模型),并最终确定决定该关系的变量中所有参数的权重(Weights)和偏差(Bias)。(2)推理是指,通过使用训练后的模型,把神经网络在训练中学习到的能力(搭建的模型)应用到之后工作中去,例如图片识别、数据分析等。
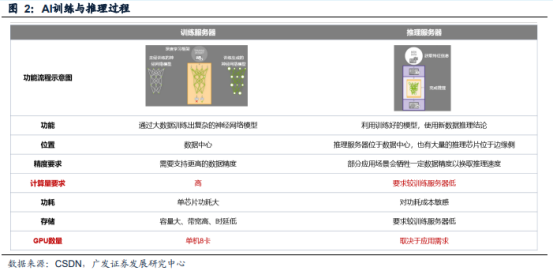
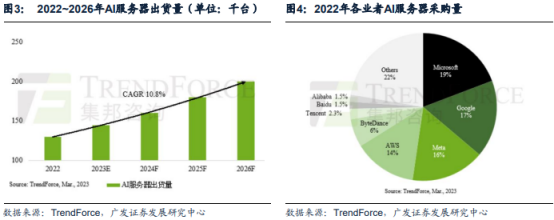
AIGC大幅提升HPC算力需求,推动AI服务器增长。AIGC大模型的训练和推理需要大量的高性能计算(HPC)算力支持,对AI服务器需求提升。据Trendforce数据,预估2022年搭载GPGPU的AI服务器年出货量占整体服务器比重近1%,即约14万台。预计2023年出货量年成长可达8%,2022~2026年CAGR达10.8%。
伴随着AI硬件市场迅速成长,相关服务器ODM厂商重要性日益凸显。英伟达于2017年启动全球顶尖ODM伙伴合作计划,与包括鸿海(富士康)在内的中国台湾服务器设计生产大厂成为合作伙伴,加速应用于AI的各种需求。通过HGX合作伙伴计划,英伟达将提供所有ODM厂商早期使用HGX参考架构、GPU运算技术以及设计准则等资源。利用HGX作为此领域的切入点,ODM伙伴厂商能与英伟达合作加快设计,并针对超大规模数据中心推出各种类型的认证GPU加速系统。英伟达工程师将通过此计划与ODM厂商密切合作,协助缩短从设计到产品部署上市的进程。

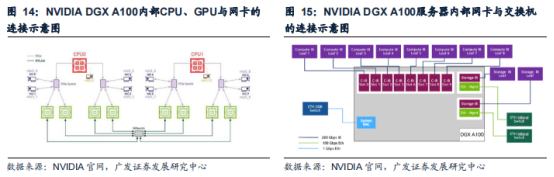
[[@pay@]]AI服务器较内部构造更为复杂,AI服务器内部产品市场空间广阔。以英伟达DGXA100为例,其内部包含了8颗A100GPU、2个64核AMDRomeCPU、2TBRAM、30TBGen4NVMESSD、6个NVIDIANVSwitch以及10个NVIDIAConnext-7200Gb/s网卡。除ODM厂商受益于服务器AI升级,成长空间广阔外,AI服务器内部的算力芯片(GPU等)、连接产品(光模块、PCIeretimer、PCB等)、存储芯片(DRAM、NAND、HBM等)市场规模都有望迎来显著提升。

算力芯片
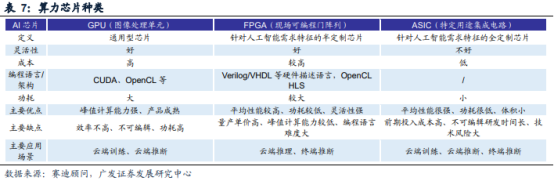
算力芯片是AI服务器中处理训练与推理的核心。在模型训练和推理的过程中需要大量的计算,其本质是在网络互联层中将大矩阵输入数据和权重相乘,因此主要的计算方式为矩阵计算。在矩阵计算中,每个计算都是独立于其他计算的,因此可以通过并行计算的方法来对计算过程进行加速。由于算力芯片相比于CPU拥有更多独立核心,因此深度学习和神经网络模型在算力芯片的加持下,采用高度并行的方式进行计算,可更高效地完成计算任务。从技术架构来看,算力芯片主要分为GPU、FPGA、ASIC三大类。其中,GPU是较为成熟的通用型人工智能芯片,而FPGA和ASIC则是针对人工智能需求特征的半定制和全定制芯片。
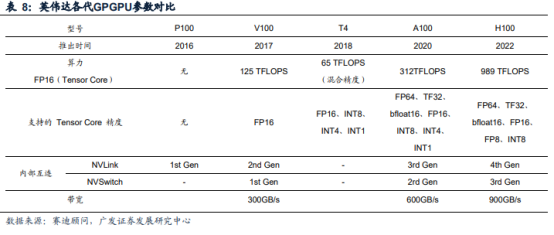
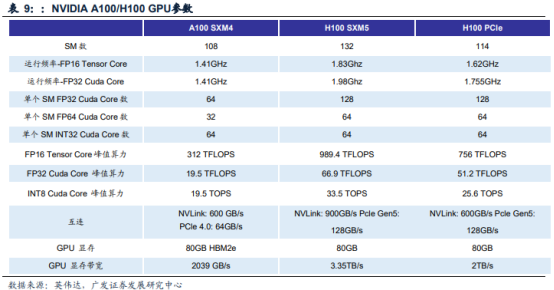
英伟达于2020年和2022年相继推出针对AI、数据分析和HPC应用场景的两款产品:A100和H100。与A100相比,H100的综合技术创新可以将大型语言模型的速度提高30倍,从而提供业界领先的对话式AI功能。具体到性能参数,同为SXM外形规格的H100/A100,半精度浮点算力(FP16tensorcore)分别为989.4/312TFLOPS,互连带宽分别为900/600GB/s。2023年GTC大会上,英伟达针对ChatGPT等大型语言模型的大规模部署,推出了H100NVL,其配备双GPUNVLink,将两张拥有94GBHBM3显存的PCIeH100GPU拼接在一起,可处理拥有1750亿参数的GPT-3大模型。与适用于GPT-3的HGXA100相比,一台搭载四对H100和双NVLINK的标准服务器速度能快10倍,可以将大语言模型的处理成本降低一个数量级。
以英伟达A100TensorCoreGPGPU为例,其架构中包括以下单元:每个GPU有7个GPC,每个GPC有7个或8个TPC,每个TPC有2个SM,每个GPC最多16个SM,总共108个SM。由多个小核心组成的SM是运算和调度的基本单元,是GPU中处理运算功能的核心。其中,每个SM有64个FP32CUDA核,64个INT32CUDA核,32个FP64CUDA核,以及4个第三代TensorCore。由于TensorCore因为专注于矩阵运算,其矩阵运算能力显著强于CudaCore,可以加速处于深度学习神经网络训练和推理速度,在维持超低精度损失的同时大幅加速推理吞吐效率,因此在模型训练与推理的过程中,TensorCore将是主要的计算内核。
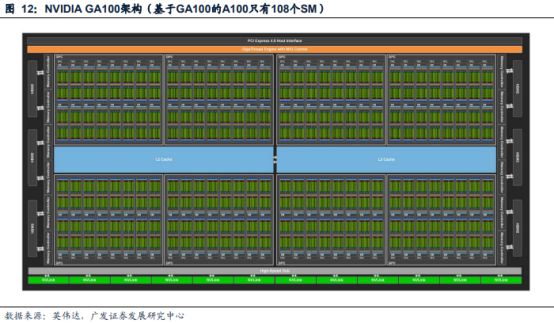
算力需求拉动GPGPU市场规模增长。在训练侧,训练一个GPT-3.5175B模型的NVIDIAA100需求为1080个;训练一个万亿参数量AI大模型对A100的需求为8521个。在推理侧,一个谷歌级应用使用GPT-3.5175B进行推理,对NVIDIAA100需求为72万个;一个谷歌级应用使用万亿参数大模型进行推理,对NVIDIAA100需求为378万个。NVIDIA作为GPGPU的龙头企业,其数据中心业务的收入可以有效反映云计算和人工智能领域对具有训练或推理功能的GPU卡的需求。2022年NVIDIA数据中心业务收入达150.10亿美元,同比增长41.50%。在AIGC需求持续提升的背景下,以GPGPU为首的算力芯片市场规模将得到显著扩容。
链接产品
光模块/光芯片是服务器集群网络的核心部件。为实现AI大模型训练、科学计算等高算力需求工作,需要使用数百甚至上千个GPU组成的计算单元作为算力基础评估、优化模型的配置和参数。为了使这样一个庞大的计算单元能够有效发挥其效率,需要使用低延迟、高带宽的网络联接各个服务器节点,以满足服务器/GPU间计算、读取存储数据的互联通信需求,同时对整个集群系统进行管理。服务器集群的网络系统包含服务器、网卡、交换机、线缆(包含光模块)等主要硬件。就网络构成来看,网卡搭载于服务器内部,网卡直接与CPU相连或通过PCIeSwitch与GPU相连;一层交换机通过服务器机身的端口与服务器内的网卡相连;线缆用于实现服务器-交换机、交换机-交换机间的连接,如果信息传输以光信号的形式实现,线缆两端均需要搭载光模块。参考从DGX-1到DGXH100的服务器迭代历程,服务器搭载网卡数量、单端口支持最高带宽均呈现出逐代次增加趋势;相应对支持更高传输速率的交换机、更高传输速率的线缆/光模块带来了增量需求。
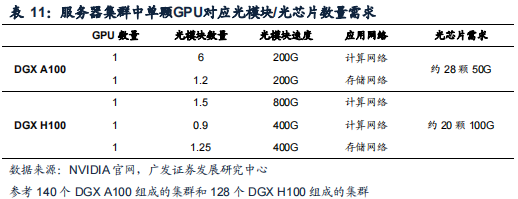
DGXA100服务器集群中单颗A100对应约7颗200G光模块需求。在140台DGXA100组成的DGXA100SuperPOD集群中,考虑计算网络和存储网络需求,共有约4000根IB网络线缆,对应约8000个端口;在全光互联方案中,平均每颗A100对应约7个200G光模块需求,其中计算、存储网络分别对应6.0、1.2个200G光模块需求,合计对应约28个50G光芯片(收发芯片)需求。
DGXH100服务器集群中单颗H100对应约1.5颗800G光模块+2颗400G光模块需求。在128台DGXH100组成的DGXH100SuperPOD集群中,考虑计算网络和存储网络需求,平均每颗H100对应约1.5个800G光模块+2个400G光模块需求,约20个100G光芯片(收发芯片)需求。
NVLink:实现GPU间高速直联。NVLink是一种GPU之间的直接互联,可扩展服务器内的多GPU输入/输出。2016年,第一代NVLink搭载基于Pascal架构的NvidiaGP100GPU发布,其传输速率可达160GB/s;目前NVLink已迭代至第四代,第四代NVIDIANVLink总带宽为900GB/s,是PCIe5.0带宽的7倍。
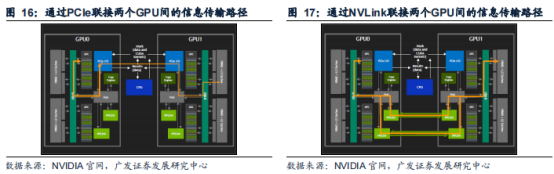
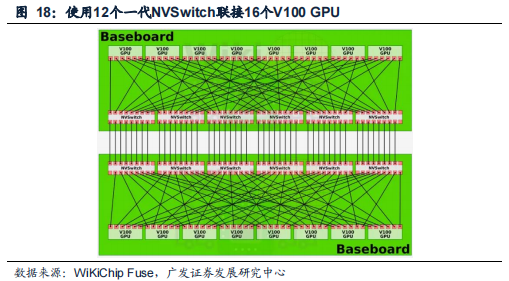
NVSwitch:实现服务器内更高带宽、更低延迟、更多GPU间通信。NVIDIA在2018GTC大会发布了首款节点交换架构——第一代NVSwitch,其上有18个NVLink端口,在单服务器节点内通过12个NVSwitch可以实现16个V100以NVLink能够达到的最高速度进行多对多GPU通信;基NVLink+NVSwitch实现服务器节点内16颗V100互联的一台DGX-2与两台通过IB互联的DGX-1(每台内有8个V100)相比,前者AI运算速度是后者的两倍以上。目前NVSwitch已经迭代到第三代,单芯片上共有64个第四代NVLink端口,支持GPU间900GB/s的通信速度,这些通过NVLinkSwitch互联的GPU可用作单个高性能加速器,拥有高达15petaFLOPS的深度学习计算性能。
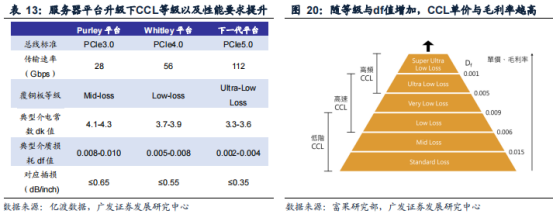
AI服务器高算力需求爆发,推动PCB单机价值量提升。PCB起中继传输的作用,是电子元器件的支撑体,服务器PCB板上通常集成CPU、内存、硬盘、电源、网卡等硬件,AI服务器在以上硬件上有不同程度的增加或升级,同时AI服务器增配4至8颗GPGPU形成GPU模组,带来PCB板单机价值量提升。AI服务器PCB板价值量提升主要来自三方面:(1)PCB板面积增加。AI服务器中除了搭载CPU的主板外,每颗GPU需要分别封装在GPU模块板,并集成到一块主板上,相比传统服务器仅使用一块主板,PCB面积大幅增加。(2)PCB板层数增加。AI服务器相对于传统服务器具有高传输速率、高内存带宽、硬件架构复杂等特征,需要更复杂的走线,因而需要增加PCB层数以加强阻抗控制等性能。(3)PCB用CCL材料标准更高。AI服务器用PCB需要更高的传输速率、更高散热需求、更低损耗等特性,CCL需要具备高速高频低损耗等特质,因此CCL材料等级需要提升,材料的配方以及制作工艺复杂度攀升。
为保障服务器内部高速稳定互联,连接产品于AI服务器中应用广泛,在ChatGPT催化迎来量价齐升。
储存芯片
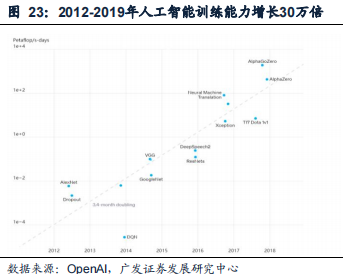
数据处理量和传输速率大幅提升是AI服务器需要高带宽的主要原因。AI服务器需要在短时间内处理大量数据,包括模型训练数据、模型参数、模型输出等。近年来,人工智能训练能力增长迅速,各种高性能应用不断涌现。根据OpenAI数据,2012-2019年,人工智能训练能力增长30万倍。如ChatGPT基于的GPT3.5大模型的参数量是175B,庞大的数据量需要在高速通道中传输。
HBM技术向提高存储容量和带宽演进,同时减小功耗和封装尺寸。HBM是目前高端GPU解决高带宽主流方案,AIGC热潮拉动HBM需求增加。AI服务器需要在短时间内处理大量数据,包括模型训练数据、模型参数、模型输出等。这些数据量通常都非常大,对高带宽需求大幅提升。GPU主流存储方案目前主要分GDDR和HBM两种方案。与GDDR方案相比,HBM方案由多个芯片垂直堆叠而成,每个芯片上都有多个内存通道,可以在很小的物理空间内实现高容量和高带宽的内存,有更多的带宽和更少的物理接口,而物理接口越少,功耗越低。同时还具有低延迟的特点,但相对而言,成本更高。HBM升级朝着不断提高存储容量、带宽,减小功耗和封装尺寸方向升级,目前已升级到HBM3。HBM方案最初由英伟达和AMD等半导体公司定义和推动,从最初的1GB存储容量和128GB/s带宽的HBM1发展到目前的24GB存储容量和819GB/s带宽。高速、高带宽的HBM堆栈没有以外部互连线的方式与计算芯片连接,而是通过中间介质层紧凑连接。以HBM2方案为例,相对于GDDR5,HBM2节省了94%的芯片面积。从带宽角度看,一个HBM2堆栈封装的带宽为307Gbyte/s,远高于GDDR5的带宽。
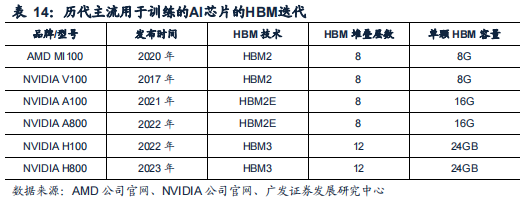
在云端高性能服务器领域,HBM已经成为了高端GPU的标配。英伟达从2017年发布的V100起,一直配置最新的HBM技术,如A100使用了HBM2E,H100使用了SK海力士的HBM3。

英伟达2016年发布的首个采用帕斯卡架构的 显卡Tesla P100已搭载了HBM2,随后Tesla V100也采用了HBM2;2017年初,英伟 达发布的Quadro系列专业卡中的旗舰GP100也采用了HBM2;2021年推出的Tesla A100计算卡也搭载了HBM2E,2022年推出了面向大陆地区的A800,同样也配置 HBM2E;2022年推出了市面上最强的面向AI服务器的GPU卡H100,采用的HBM3。

AI服务器需要高带宽支持,HBM是目前高端GPU解决高带宽主流方案, 在AIGC热潮拉动下,HBM需求增加。
报告来自:
广发证券——AI的IPHONE时刻
风险提示:本文中提及的相关个股基于公开数据和智能算法生成。是自动采集最新动态、大新闻,并且自动根据上市公司的经营情况自动匹配,只做列表跟查询之用,仅供参考。投资者应独立决策并承担投资风险。
本文版權歸屬原作者/機構所有。
當前內容僅代表作者觀點,與本平台立場無關。內容僅供投資者參考,亦不構成任何投資建議。如對本平台提供的內容服務有任何疑問或建議,請聯絡我們。
