
Single-card inference throughput reaches 2,300 Tokens/s, Ascend AI cloud services are rewriting the rules of computing power.


Half a month ago at HDC 2025, Huawei Cloud fully launched the Ascend AI cloud service based on the CloudMatrix384 super node, causing quite a stir both within and outside the industry.
What impressed us the most was a set of data: Compared to non-super nodes, the single-card throughput of the CloudMatrix384 super node increased from 600Tokens/s to 2300Tokens/s; the output latency of incremental Tokens also reduced from the original 100ms to below 50ms.
To explore the technical secrets behind these metrics, we found a paper co-authored by Huawei and Silicon Flow, which detailed the architectural innovations of CloudMatrix and the production-level practices of CloudMatrix384. The test results stated—the single-card throughput when running DeepSeek-R1 has already surpassed that of NVIDIA's H100.
As the industrial narrative of large models shifts from training to inference, what does the record-breaking single-card throughput capability of the new-generation Ascend AI cloud service mean for the computing power industry?
01 How was it achieved? A "victory of systems engineering"
The first question to answer is: How did the CloudMatrix384 super node achieve a nearly 4x performance leap in single-card throughput?
The answer lies in engineering innovation.
To improve the inference performance of large models, traditional approaches focus on single-point optimizations: increasing the number of nodes to enhance inference capability through stacked computing power; quantizing and pruning models to reduce unnecessary calculations; optimizing KV Cache to accelerate incremental inference; and using automatic graph optimization tools to fuse multiple operators into a single efficient kernel function, reducing intermediate memory copies...
However, as the parameter count of large models continues to grow, MoE architectures are widely adopted, and context lengths expand rapidly, single-point optimizations are revealing increasing limitations: for example, communication bottlenecks in multi-card parallel inference, poor coupling between chips and memory, resource wastage in "whole-card" scheduling, etc. Both throughput performance and inference costs are struggling to meet the rapidly growing demands of application deployment.
The CloudMatrix384 super node proposes a new architectural design, differing from simple "computing power stacking," and further achieves three principles: everything can be pooled, everything is peer-to-peer, and everything is composable.
Understanding these three principles reveals the value of engineering innovation.
Everything can be pooled: Through a unified, ultra-high-performance network (MatrixLink), resources such as NPUs, CPUs, memory, and networking are decoupled to form independently scalable resource pools.
Everything is peer-to-peer: Unlike the traditional GPU-centric computing paradigm, all resources in the pool are no longer in a "master-slave" relationship but adopt a more efficient and flexible peer-to-peer architecture.
Everything is composable: This means all resources pooled by the CloudMatrix384 super node can be flexibly allocated and combined like building blocks according to different task requirements.
In summary: The CloudMatrix384 super node interconnects 384 Ascend NPUs and 192 Kunpeng CPUs through the new high-speed network MatrixLink in a fully peer-to-peer manner, forming a super "AI server" with ultra-large bandwidth, ultra-large memory, and ultra-high computing power.
The reason for adopting a fully peer-to-peer interconnected architecture is to match the training and inference tasks of large models, especially those with MoE hybrid architectures.
In traditional cluster mode for inference, all "experts" must be allocated to each single card, computing every problem once, resulting in each "expert" receiving only a small amount of computing and communication capability.
In contrast, a single CloudMatrix384 super node can support hundreds of experts for parallel inference, enabling a "one-card-one-expert" model, where each card deploys only one "expert" to centrally process all related questions, increasing the size of each inference batch, reducing per-unit scheduling overhead, and significantly improving inference efficiency. Additionally, the super node can support "one-card-one-operator tasks," flexibly allocating resources to enhance task parallel processing, reduce waiting times, and increase the effective utilization rate of computing power (MFU) by over 50%.
Another example is the two phases of large model inference: Prefill and Decode. Prefill generates KV Cache, while Decode uses and updates KV Cache. The decoupled shared memory pool of the CloudMatrix384 super node can store more KV Cache, allowing Prefill and Decode tasks to access KV Cache faster and more evenly, significantly reducing system latency.
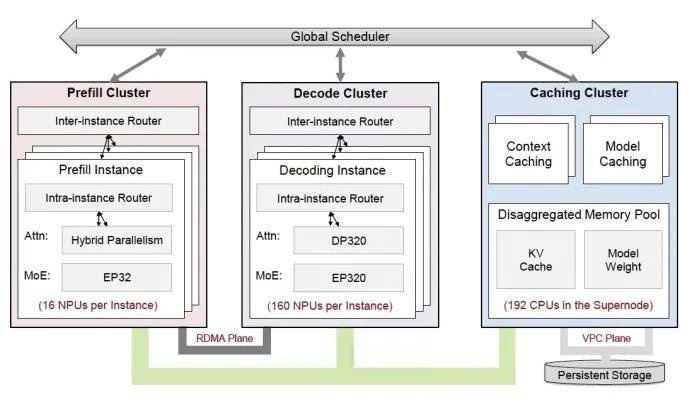
In other words, the single-card inference throughput of 2300Tokens/s and output latency below 50ms can be attributed to a "victory of systems engineering." Against the backdrop of Moore's Law gradually slowing and limited improvements in single-card computing power, reconstructing the computing interconnection architecture has achieved optimal system-level performance, completing the leap of domestic computing power from "usable" to "practical."
02 What has changed? Large model deployment "crossing the hill"
Entering 2025, the role of large models has rapidly transformed, moving out of the lab and accelerating deployment in government, finance, healthcare, energy, and other fields.
However, during deployment, real-world issues such as slow response times, low throughput, and high costs have become unavoidable "bottlenecks" for many enterprises, not only slowing business momentum but also raising the threshold for technological returns. If "training well" is an arms race, "affordability" is the industry's inflection point.
Huawei's "overtaking on the curve" in engineering innovation provides a validated solution paradigm for the challenges of large model deployment.
First, from the perspective of large model training.
The training tasks of trillion- and ten-trillion-parameter large models have spurred demand for clusters of tens of thousands or even hundreds of thousands of cards, also bringing a "crisis" of computing power shortages.
One optimistic piece of news is that in cloud data centers, the CloudMatrix384 super node can cascade up to 432 super nodes into a massive 160,000-card cluster, providing 10 PFlops of computing power. A key metric here is linearity—whether performance can "scale proportionally" as the number of nodes increases. Currently, the linearity of the CloudMatrix384 10,000-card cluster has exceeded 95%, achieving a near 1:1 ratio between performance improvement and resource expansion, capable of simultaneously supporting 1,300 billion-parameter large model trainings.

To help customers optimally use resources, the CloudMatrix384 super node Ascend AI cloud service also supports integrated deployment of training and inference computing power, such as the "inference by day, training by night" model, or the "40-day stable training, 10-minute quick recovery" capability, ensuring stability during long-term training and rapid recovery after interruptions.
A more profound impact lies in the inference aspect.
As mentioned earlier, the single-card throughput of the CloudMatrix384 super node has increased to 2300Tokens/s, and along with it, inference costs have also changed.
According to calculations by a Zhihu user: With a single-card throughput of 2300Tokens/s, 8.28 million Tokens can be generated per hour. At an hourly rental cost of 15 yuan, the cost per million Tokens is approximately 1.8 yuan, making the inference cost even lower than NVIDIA's GPU solutions.
In the field of large model inference, there is a famous "impossible triangle"—low inference cost, fast response speed, and high output accuracy are almost impossible to achieve simultaneously.
The CloudMatrix384 super node provides a negative answer to this. Taking DeepSeek-R1 as an example, with 256 fixed experts and 32 shared experts, the "one-card-one-expert" model of the CloudMatrix384 super node perfectly matches the inference needs of DeepSeek-R1, ensuring inference performance while still achieving high throughput and low latency goals.
In the large model competition where "inference cost determines the final victory," the CloudMatrix384 super node can be said to be the "optimal solution" at this stage, technically overcoming the triple contradiction of response speed, throughput capability, and output accuracy, removing the "mountain" of large model deployment for industries across the board.
There are many corroborating cases.
Sina, based on the CloudMatrix384 Ascend AI cloud service, built a unified inference platform for its "Smart Xiaolang" intelligent service system, improving inference delivery efficiency by over 50%.
FaceWall Intelligence used the CloudMatrix384 Ascend AI cloud service to achieve a 2.7x improvement in the inference performance of its "Little Cannon" model.
360 is initiating comprehensive cooperation with the Ascend AI cloud service, with Nano AI Search already enabling efficient collaboration among hundreds of large models to provide users with super AI search services.
03 Final thoughts
Barclays Bank stated in a research report in early 2025: AI inference computing demand will rapidly increase, expected to account for over 70% of total general AI computing demand, with inference computing demand even significantly surpassing training, reaching 4.5 times the latter.
Whoever solves inference efficiency will dominate large model deployment.
Re-examining the CloudMatrix384 super node Ascend AI cloud service from this perspective, it is not just a leap in technical metrics but a deep validation of system-level engineering innovation, redefining the future computing paradigm: "chip performance" is no longer the sole measure, but new competitive standards built on "overall system efficiency," "inference cost," and "model structure adaptability" open a more efficient, inclusive, and sustainable technological path for the entire AI industry.
As of now, the Ascend AI cloud service based on the CloudMatrix384 super node has been launched in Huawei cloud data centers in Wuhu, Gui'an, Ulanqab, Helinge'er, and other locations, relying on a fiber-optic backbone network with hundreds of TB-level bandwidth, covering 19 urban clusters nationwide within a 10-millisecond latency circle. Through the victory of engineering innovation, it is meeting the industrial deployment needs of the large model era.
The copyright of this article belongs to the original author/organization.
The views expressed herein are solely those of the author and do not reflect the stance of the platform. The content is intended for investment reference purposes only and shall not be considered as investment advice. Please contact us if you have any questions or suggestions regarding the content services provided by the platform.
