
iM Securities: Is TSMC Bottlenecking Nvidia's Short-Term Growth?
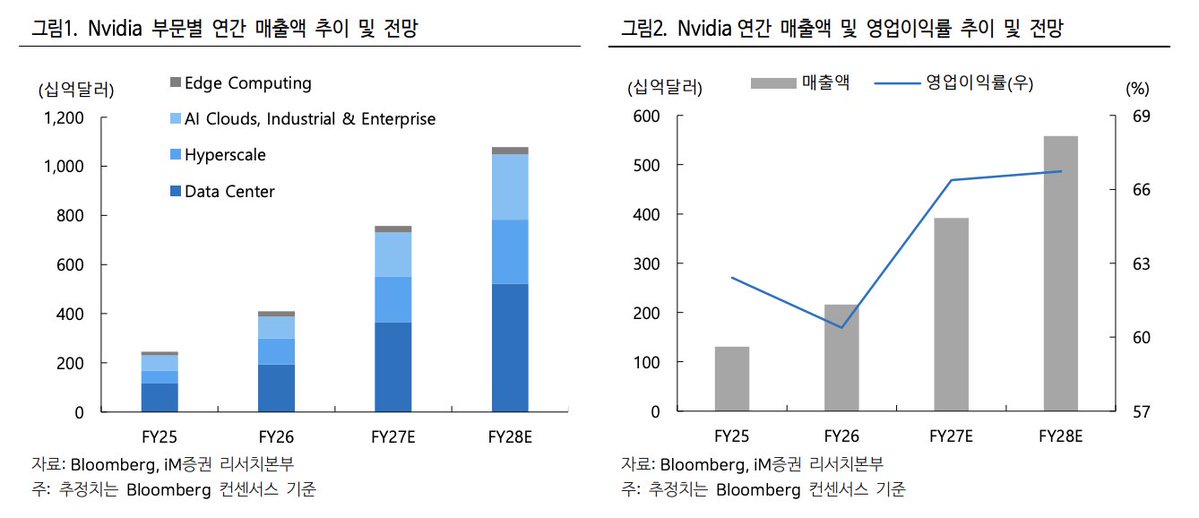
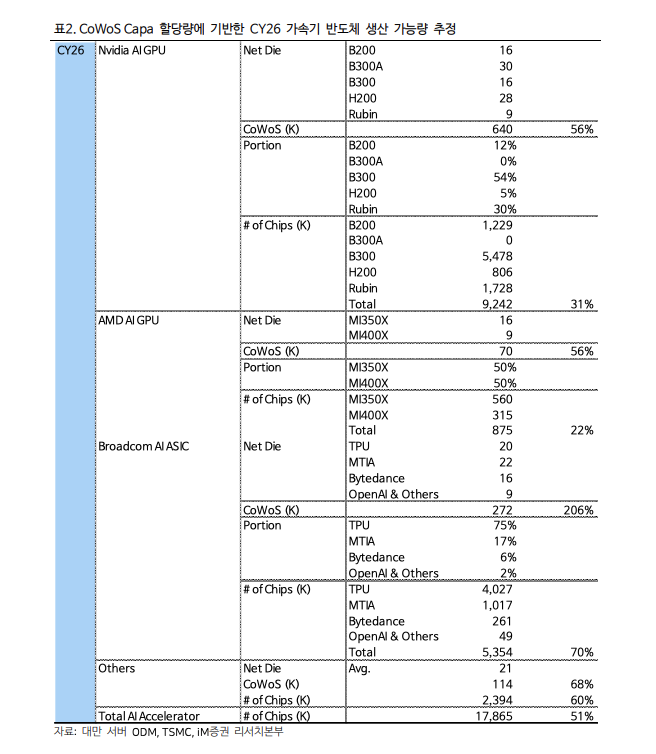
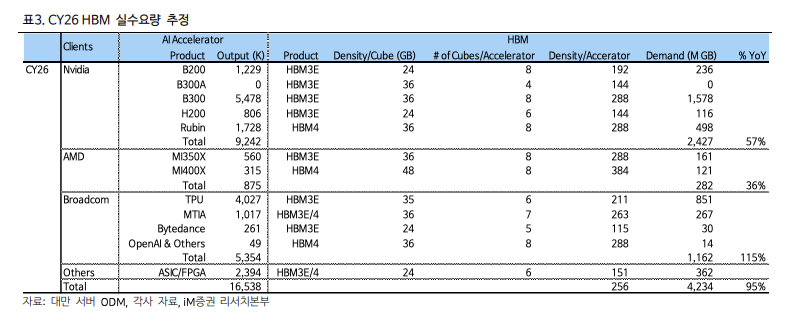
> CoWoS Wafer Revisions: Due to slower-than-expected capacity expansion by TSMC $Taiwan Semiconductor(TSM.US) and other CoWoS suppliers, iM Securities lowered its CY26 global CoWoS allocation forecast for AI accelerators from 1,380K to 1,096K wafers. Consequently, Nvidia's projected AI GPU production for the year has been cut from 11.14 million units (YoY +57%) to 9.24 million units (YoY +31%).> Rubin Delays: Most notably, production projections for the next-generation Rubin GPU have been slashed in half, from 3 million units down to 1.5 million units.> HBM Market Impact: Lower accelerator production drops total CY26 HBM demand from 4.89 billion GB to 4.23 billion GB. Memory manufacturers have adjusted their production down slightly to 4.33 billion GB, factoring in lower-than-expected demand and lower margins compared to conventional DRAM.> Nvidia’s upcoming next-generation AI accelerator, the Rubin Ultra (slated for CY27), is facing technical hurdles that may force a significant specification downgrade. While still under negotiation between Nvidia and memory vendors, a 384GB scaled-down version is being considered instead of the original 1TB (1,024GB) target.> CoWoS-L Size Limitations: The physical limit of the CoWoS-L interposer is 8,150 mm^2. The original 4-die plan requires 6,750mm^2. While mathematically possible, scaling the interposer up dramatically increases substrate warpage, concentrates stress on the corners, degrades bump fatigue life, and tanks packaging yields. Returning to a 2-die architecture automatically drops the maximum HBM cubes from 16 to 8.> TSMC's CoPoS Alternative is Too Late: TSMC’s next-gen solution to bypass this size limit is CoPoS (Chip on Panel on Substrate). However, because TSMC is only just beginning to select equipment and component vendors, mass production is not expected until the second half of 2028 (2H28). This leaves a packaging bottleneck that will stress Nvidia's growth through next year.> HBM4E Stacking Yields: Memory manufacturers are also struggling with the production yields of stacking 16-layer HBM4E, though this is flagged as a memory vendor issue rather than a TSMC-inflicted constraint.> Total AI Accelerator chip volume for CY26 is projected to hit 17,865K (17.87M) units, reflecting a 51% YoY growth.> Nvidia $NVIDIA(NVDA.US) commands 56% of the total CoWoS capacity allocation (640K wafers), yielding 9,242K chips (+31% YoY).> Broadcom $Broadcom(AVGO.US) captures 272K CoWoS wafers (a massive 206% increase), resulting in 5,354K chips (+70% YoY). This is heavily anchored by Google's TPU, which takes 75% of Broadcom's share (4,027K chips). Meta's MTIA accounts for 1,017K chips.> AMD $AMD(AMD.US) AI GPUs take up 70K wafers, translating to 875K chips (+22% YoY), split between MI350X (560K) and MI400X (315K).> Global HBM demand for CY26 is expected to reach 4,234 million GB (4.23B GB), marking an explosive 95% YoY growth.> Nvidia alone consumes 2,427M GB (roughly 57% of total market demand).> Broadcom represents 1,162M GB of HBM demand (+115% YoY), dominated heavily by the TPU at 851M GB.> AMD accounts for 282M GB of demand, with the upcoming MI400X utilizing ultra-dense HBM4 configurations (384GB per accelerator using 48GB cubes).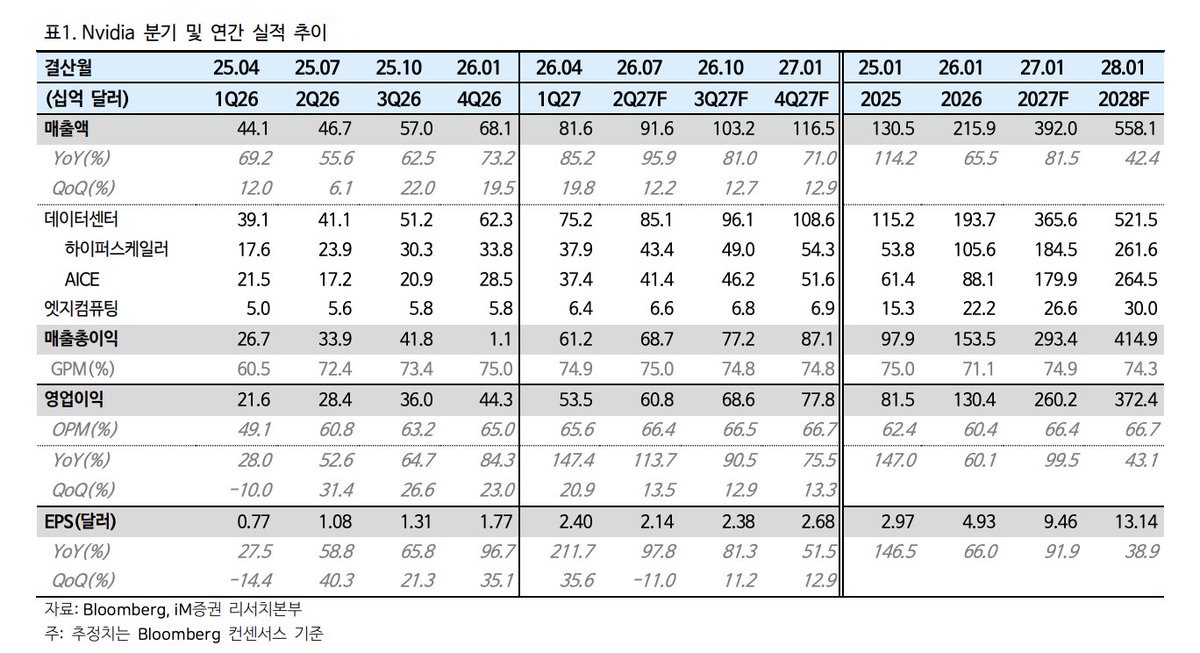
The copyright of this article belongs to the original author/organization.
The views expressed herein are solely those of the author and do not reflect the stance of the platform. The content is intended for investment reference purposes only and shall not be considered as investment advice. Please contact us if you have any questions or suggestions regarding the content services provided by the platform.
Post your comment

No Comments