
AI inference is shipping, yet as much as 99% of compute still sits idle. The core bottleneck is the 'memory wall' — data movement can’t keep up with compute, so GPUs spend far more time waiting to be fed than crunching numbers. For example, generating one token may take ~10 μs of compute but ~9 ms to load data, meaning most of the time is spent waiting.
Fixing this is a two-step process: quick wins in the near term, and a more structural, tech-led cure over the medium to long term.
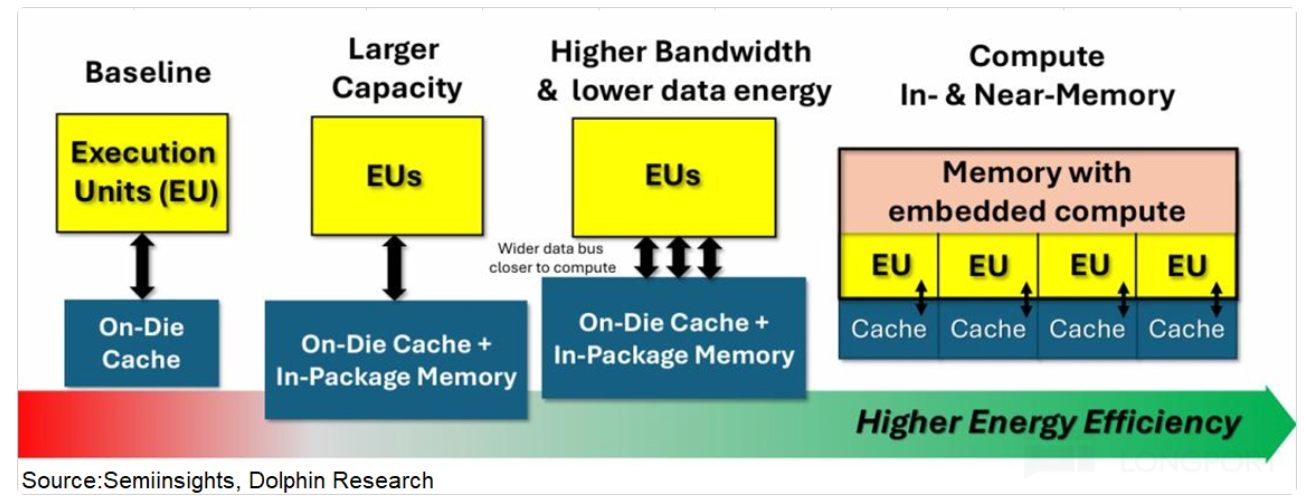
Near term, combine 'faster pipes + shorter distance'. On one hand, upgrade HBM (GPU-attached DRAM) from 12-Hi to 16-Hi to push bandwidth to 16–32 TB/s, effectively speeding up and widening data lanes.On the other hand, add 3D-stacked SRAM adjacent to the GPU to keep hot data nearby, cutting latency from ~100 ns to ~2 ns.
SRAM handles speed-sensitive transfers, while HBM provides capacity. NVIDIA’s acquisition of Groq targets SRAM know-how, and the Rubin platform slated for 2H26 is set to integrate this, boosting memory throughput.
Over the medium to long term, move to compute-in-memory (CIM), embedding some compute into storage so data isn’t shuttled back and forth. This removes the memory wall at the source.CIM hasn’t been deployed in data centers yet, with rollouts expected after 2027.
With HBM4 entering mass production in 2026 and SRAM commercialization ramping, followed by CIM adoption, the 99% idle compute problem should gradually ease.AI inference can then run much closer to full throttle.
The copyright of this article belongs to the original author/organization.
The views expressed herein are solely those of the author and do not reflect the stance of the platform. The content is intended for investment reference purposes only and shall not be considered as investment advice. Please contact us if you have any questions or suggestions regarding the content services provided by the platform.
