
AI 推理都落地了,卻還是有的 99% 算力在空轉?我們之前的文章裏提到了一個核心癥結: “內存牆”—— 數據傳輸速度遠跟不上算力增長,GPU 等着數據 “投餵” 的時間,比實際計算時間多幾百倍。比如生成一個 Token,計算僅需 10 微秒,加載數據卻要 9 毫秒,大部分時間都在 “等材料”。
解決這個問題分兩步走,短期見效快,中長期靠技術根治。
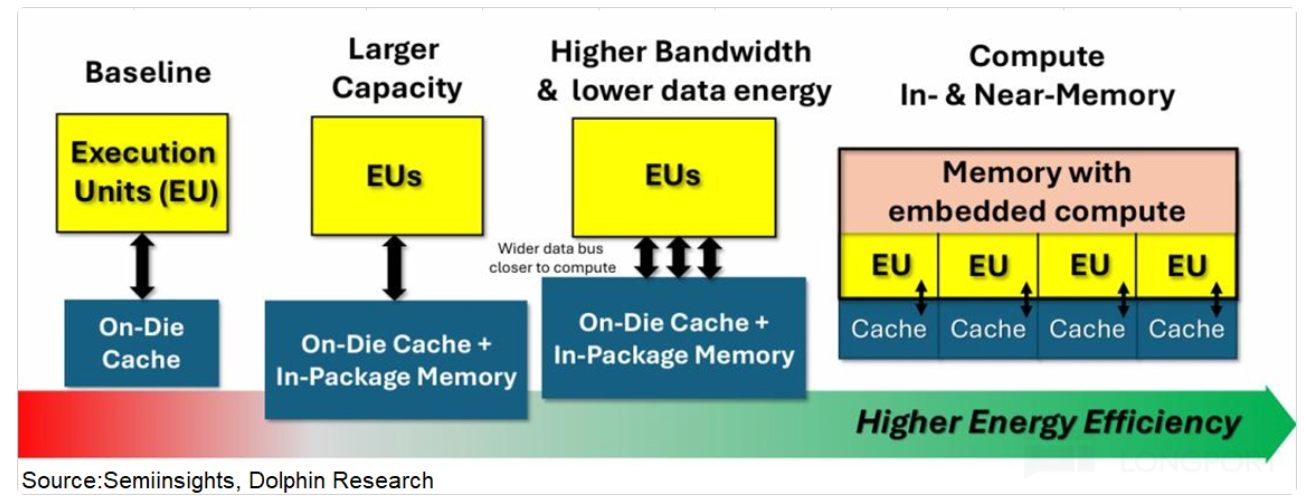
短期靠 “提速 + 縮距” 組合拳:一方面給 HBM(GPU 專用顯存)升級,從 12-Hi 堆疊提到 16-Hi,帶寬衝到 16-32TB/s,讓數據傳輸 “提速加寬”;另一方面搭配 3D 堆疊 SRAM,把高頻數據直接放在 GPU 旁邊,傳輸延遲從 100ns 壓到 2ns,兩者分工 ——SRAM 負責 “快傳”,HBM 負責 “多存”。英偉達收購 Groq 就是為了 SRAM 技術,2026 年下半年的 Rubin 芯片會融入這項技術,直接提升存力速度。
中長期則靠存算一體技術,把部分算力嵌進存儲裏,數據不用來回搬運,在存儲中就能完成計算,從根源消除 “內存牆”。不過這項技術目前還沒在數據中心落地,預計 2027 年後逐步推廣。
隨着 HBM4 2026 年量產、SRAM 技術商用,再加上後續存算一體落地,99% 算力閒置的問題才可能會逐步緩解,讓 AI 推理真正 “滿負荷幹活”。
本文版權歸屬原作者/機構所有。
當前內容僅代表作者觀點,與本平台立場無關。內容僅供投資者參考,亦不構成任何投資建議。如對本平台提供的內容服務有任何疑問或建議,請聯絡我們。
發表你的評論

暫無評論